Through this work our aim was to create a model which is able to predict COVID-19 related fake news in multiple languages without any need for COVID specific parallel data.
Current methods of doing this involve using large models like BART, instead we wanted to have a model which is much smaller in size, therefore has the ability to do fast inference (even on a smartphone).
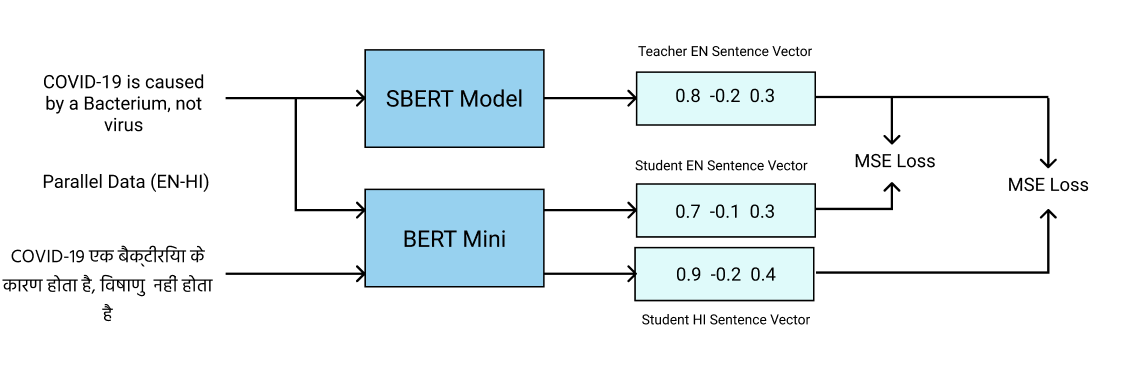
In this project we demonstrate a way of training an extremely small BERT model (mini BERT) using labels from a larger model (Sentence BERT) using Knowledge Distillation method. Doing this allows us to train the model to have a shared embedding space between languages and also learn the rich semantics of a larger SBERT model, which are very effective in sentence level classification tasks.
Since the model has very few parameters, it is very fast during inference and can be useful for running on browser, smaller devices.
This work got accepted in the AI4SG Workshop in IJCAI 2021